
That day when you receive a ping like.
“Hey, what happened to this request. It was quite important. Dated back 14th September. Could you explain me that? Seems like BC online was down. Keep in mind that this log could have been collected even the day after”.

Errore invio dati ordine 503:{“error”:{“code”:”Application_ServiceUnavailable”,”message”:”The session could not be retrieved from the server. The application will close. CorrelationId: 173959cf-96d4-476f-8d32-ee084f359237.”}}
Quoting Kennie’s advice to go through the Kusto Detective Agency (KDA) at EMEA Directions 2023 next week, this could be part of a Dynamics 365 Business Central Kusto Detective Agency (I want the copyright ;-).

So now, back to the problem. You can separate the entire humanity in 2 categories: with or without telemetry.
The one without telemetry: “Sorry, we do not have any kind of log for that, and we cannot give you any appropriate answer, we could open a request to Microsoft but bear in mind that there will be a delay in answer, accordingly to its severity”.
Then there are the braves that DO telemetry.
First rule of the good telemetry engineer: retention policy. Do not spare few bucks to have more data to analyze. 30 days of retention are typically not enough for such environments. 60 or 90 days should be the right choice if you have a long implementation time for different task in a project.
In this specific case: the first qualified answer “No worries, we have applied a 90-day retention policy and if anything happened that day, I would find this out”.
FOCUS AND ISOLATE
There are 2 ways to approach this:
- Find out all HTTP 503 (signal RT0008) within 2 days range (14th and 15th September) and if you have a small number of these then move to the zoom out section.
- [MY PREFERRED]. Use the correlationId to match with the session_Id in all telemetries, within 2 days range.
traces
| where timestamp between (datetime(2023-09-13T22:00:31Z)..datetime(2023-09-15T22:00:31Z))
| where session_Id == “173959cf-96d4-476f-8d32-ee084f359237”
NOTE: remember that datetime uses UTC and that was happening in Central European Summer Time (CEST) hence we have to apply a -2 hours difference to capture both 14th and 15th September.
Query result: precisely 1 record
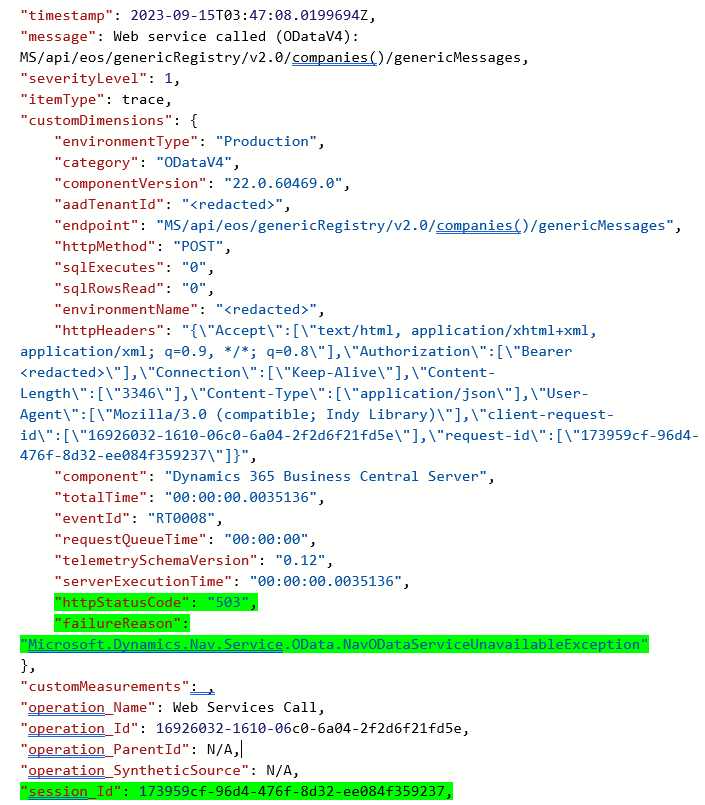
Bingo. That request tried to get in at 2023-09-15T03:47:08.0199694Z UTC but received a sorry-we-are-not-available-at-the-moment by the server.
But why? After finding the record we move to the next phase: zoom out within a specific time frame to check what was going on.
ZOOM OUT
To better understand what was happening at that time, typically I am opening to a higher window and looking at ALL telemetry events that have been sent through that time frame, to look if they are of any interest. In this case, let’s say 2 seconds before and 2 seconds after.
traces
| where timestamp between (datetime(2023-09-15T03:47:07.0199694Z)..datetime(2023-09-15T03:47:09.0199694Z))
| project timestamp, customDimensions.eventId, message
Results:

Answer to customer (with evidence) “There was a silent hotfix deployed by Microsoft during the night that caused the service to be temporarily unavailable because the Base Application was finishing synchronizing. The synchronization process ended 1 second right after the call, to be precise. – What a bad luck -.

I fully understand that you are working 24/7 but Microsoft unfortunately typically patches application and platform during the update window without any way to reschedule. This is duly written in the Microsoft documentation. If you like, I could create a weekly scheduled alert that send you a list of all HTTP 503, just to be sure you review them, if and when they happen, and proactively reschedule calls within the appropriate time.”
(Well, the answer was not exactly like that, but you got my point).
CONCLUSION AND TAKEAWAYS
- Always keep in mind that Microsoft is still deploying applications and platform hotfixes through pipeline when it is more convenient or generally needed. This might even happen every day in a week, even though Microsoft is trying to limit them as much as possible and cannot be controlled by partners or a tenant being kept outside pipelines. Such online service operations and their cadence are described officially here: https://learn.microsoft.com/en-us/dynamics365/business-central/dev-itpro/service-overview#service-operations and resumed in the sentence “Service operations happen all day, every day, to always provide best experience”. Point take. If you search the IDEAS site, you will find out several entries requesting a better control when such application and platform fixes are deployed.
- When planning telemetry retention policy, start with a short retention period and keep costs under control. After an entire company business cycle (typically 1 month, if you do not have seasonality), decide the retention strategy and its review in time. In new deployments or customers that needs more refinements in performance, try to leave it 60/90 days. You will never know what kind of regression or information you might need. And if there are no data (just to spare few bucks) there won’t be any joy.
This is one of the typical real-life scenarios where telemetry would help in provide reactive and/or proactive support to your business. Me and Stefano Demiliani have more of these stories to share with you at the upcoming Directions EMEA 2023 in our session:

Hope to see you in Lyon… PARBLEU!!!
